在默认情况下,debian并没有安装vim,所以当我们使用vi的时候并没有使用我们想用的vim,而很多教程貌似忽略了这一点造成新手的使用障碍,及时在鸟叔的linux也并没有说明这个问题。
典型的特征是,我们的右下角不显示行号,左下角也不显示文件信息,按i也无法进入insert模式,总归来说,我们只需要执行
apt-get install vim
安装下vim,即可。
在默认情况下,debian并没有安装vim,所以当我们使用vi的时候并没有使用我们想用的vim,而很多教程貌似忽略了这一点造成新手的使用障碍,及时在鸟叔的linux也并没有说明这个问题。
典型的特征是,我们的右下角不显示行号,左下角也不显示文件信息,按i也无法进入insert模式,总归来说,我们只需要执行
apt-get install vim
安装下vim,即可。
今天要在自己的虚拟机上部署debian,在安装的过程中出现任何镜像都无法连接的怪异现象,网卡模式使用的是桥接,分配IP是192.168.0.11
问题搜索了很久没有解决,不过临时想了想就把avast的防火墙关闭了,结果VM就可以连接了。
由于自己并不清楚vm桥接网卡的连接通信方式,一直以为这个连接是avast管不了的,结果发现还是与其有关。
具体查看avast日志,发现如下拦截
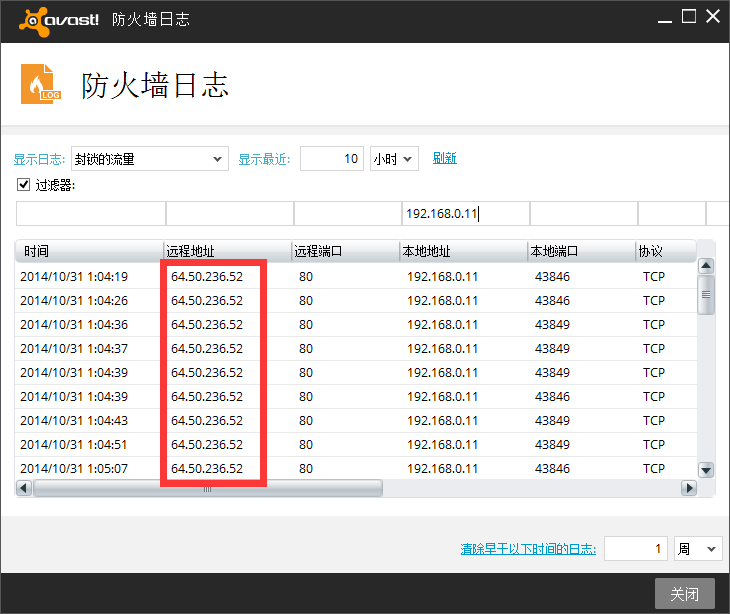
该IP地址正是debian源的IP,可以发现avast这里面全部都给拦截了,而拦截的规则竟然是找不到规则
我晕,你找不到规则也不要随便拒绝别人的请求啊喵
果断在设置里面修改默认为允许。
今日发现维护在Openshift的网站出现了503错误,上网查找相关资料发现这个问题是由于openshift经常更新所导致的。
解决办法如下,通过Xshell(或者其他类似软件)登录到shell中
重新启动服务,可以用如下命令
ctl_all restart
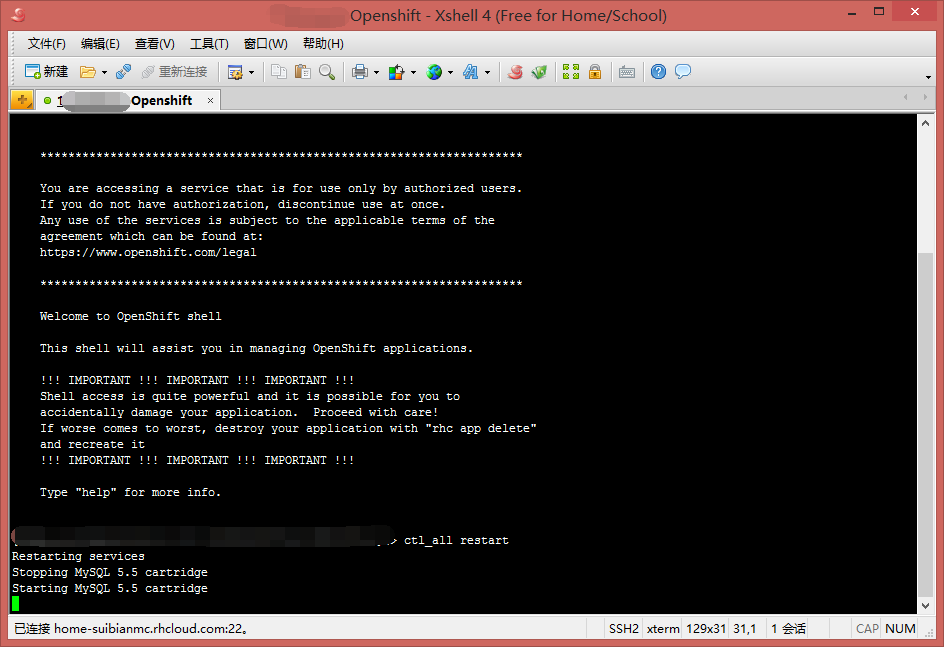
通过该命令重启服务一般就会恢复正常了,其他可用的命令还有
ctl_all start
ctl_all stop
ctl_all restart
ctl_all status
以上代码依次为1启动、2停止、3重启、4查看应用,出现“503 Service Temporarily Unavailable”一般是执行启动和重启就行了。
%a 浮点数、十六进制数字和p-记数法(C99)
%A 浮点数、十六进制数字和p-记法(C99)
%c 一个字符(char)
%C 一个ISO宽字符
%d 有符号十进制整数(int)(%ld、%Ld:长整型数据(long),%hd:输出短整形。)
%e 浮点数、e-记数法
%E 浮点数、E-记数法
%f 单精度浮点数(默认float)、十进制记数法(%.nf 这里n表示精确到小数位后n位.十进制计数)
%g 根据数值不同自动选择%f或%e.
%G 根据数值不同自动选择%f或%e.
%i 有符号十进制数(与%d相同)
%o 无符号八进制整数
%p 指针
%s 对应字符串char*(%s == %hs == %hS 输出 窄字符)
%S 对应宽字符串WCAHR*(%ws == %S 输出宽字符串)
%u 无符号十进制整数(unsigned int)
%x 使用十六进制数字0f的无符号十六进制整数
%X 使用十六进制数字0f的无符号十六进制整数
%% 打印一个百分号
%I64d
用于INT64 或者 long long
%I64u
用于UINT64 或者 unsigned long long
%I64x
用于64位16进制数据
①%:表示格式说明的起始符号,不可缺少。
②-:有-表示左对齐输出,如省略表示右对齐输出。
③0:有0表示指定空位填0,如省略表示指定空位不填。
④m.n:m指域宽,即对应的输出项在输出设备上所占的字符数。n指精度。用于说明输出的实型数的小数位数。为指定n时,隐含的精度为n=6位。
⑤l或h:l对整型指long型,对实型指double型。h用于将整型的格式字符修正为short型。
---------------------------------------
格式字符
格式字符用以指定输出项的数据类型和输出格式。
①d格式:用来输出十进制整数。有以下几种用法:
%d:按整型数据的实际长度输出。
%md:m为指定的输出字段的宽度。如果数据的位数小于m,则左端补以空格,若大于m,则按实际位数输出。
②o格式:以无符号八进制形式输出整数。对长整型可以用”%lo”格式输出。同样也可以指定字段宽度用“%mo”格式输出。
例:
main()
{ int a = -1;
printf(“%d, %o”, a, a);
}
运行结果:-1,177777
程序解析:-1在内存单元中(以补码形式存放)为(1111111111111111)2,转换为八进制数为(177777)8。
③x格式:以无符号十六进制形式输出整数。对长整型可以用”%lx”格式输出。同样也可以指定字段宽度用”%mx”格式输出。
④u格式:以无符号十进制形式输出整数。对长整型可以用”%lu”格式输出。同样也可以指定字段宽度用“%mu”格式输出。
⑤c格式:输出一个字符。
⑥s格式:用来输出一个串。有几中用法
%s:例如:printf(“%s”, “CHINA”)输出”CHINA”字符串(不包括双引号)
%ms:输出的字符串占m列,如果字符串本身长度大于m,则突破获m的限制,将字符串全部输出。若串长小于m,则左补空格。
%-ms:如果串长小于m,则在m列范围内,字符串向左靠,右补空格。
%m.ns:输出占m列,但只取字符串中左端n个字符。这n个字符输出在m列的右侧,左补空格。
%-m.ns:其中m、n含义同上,n个字符输出在m列范围的左侧,右补空格。如果n>m,则自动取n值,即保证n个字符正常输出。
⑦f格式:用来输出实数(包括单、双精度),以小数形式输出。有以下几种用法:
%f:不指定宽度,整数部分全部输出并输出6位小数。
%m.nf:输出共占m列,其中有n位小数,若数值宽度小于m左端补空格。
%-m.nf:输出共占m列,其中有n位小数,若数值宽度小于m右端补空格。
⑧e格式:以指数形式输出实数。可用以下形式:
%e:数字部分(又称尾数)输出6位小数,指数部分占5位或4位。
%m.ne和%-m.ne:m、n和”-”字符含义与前相同。此处n指数据的数字部分的小数位数,m表示整个输出数据所占的宽度。
⑨g格式:自动选f格式或e格式中较短的一种输出,且不输出无意义的零。
---------------------------------------
关于printf函数的进一步说明:
如果想输出字符”%”,则应该在“格式控制”字符串中用连续两个%表示,如:
printf(“%f%%”, 1.0/3);
输出0.333333%。
---------------------------------------
对于单精度数,使用%f格式符输出时,仅前7位是有效数字,小数6位.
对于双精度数,使用%lf格式符输出时,前16位是有效数字,小数6位.
—————————–可变宽度参数
对于m.n的格式还可以用如下方法表示(例)
char ch[20];
printf(“%*.*s\n”,m,n,ch);
前边的*定义的是总的宽度,后边的定义的是输出的个数。分别对应外面的参数m和n 。我想这种方法的好处是可以在语句之外对参数m和n赋值,从而控制输出格式。
最近学校一直在教java,老觉得别的IDE用的各种不爽,还是想用自己的Sublime,在网上查找了一些方法,发现都是在sublime调试输出的,这样的缺点就是无法接受用户输入,所以我稍作改变,调用一个cmd出来解决这个问题。
1. 首先需要配置java的path环境变量
这个很好说,环境变量里配置就好了,如果不会自行百度。
2. 打开jdk的bin目录,新建runJava.bat,内容如下:
@ECHO OFF
cd %~dp1
ECHO Compiling %~nx1.......
IF EXIST %~n1.class (
DEL %~n1.class
)
javac %~nx1
IF EXIST %~n1.class (
ECHO -----------OUTPUT-----------
start cmd /k "cd %~dp1&java %~n1"
)
3. 回到Sublime,打开菜单Preference,选择Browse Packages,找到java文件夹下的JavaC.sublime-build文件,打开编辑。
{
"cmd": ["runJava.bat", "$file"],
"file_regex": "^(...*?):([0-9]*):?([0-9]*)",
"selector": "source.java",
"encoding": "cp936"
}
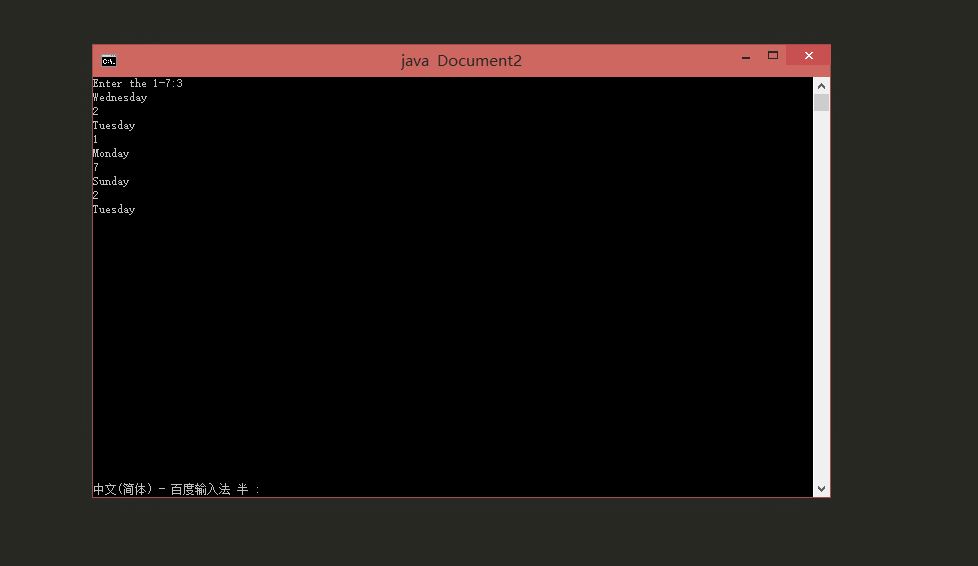
4. 然后我们随便写一个需要用户输入的java程序,比如
import java.util.Scanner;
public class Document2{
public static void main ( String[] args ){
int number = 0;
String week = "";
Scanner input = new Scanner (System.in);
System.out.print("Enter the 1-7:");
while(input.hasNext()){
number = input.nextInt();
switch (number){
case 1:
week = "Monday";
break;
case 2:
week = "Tuesday";
break;
case 3:
week = "Wednesday";
break;
case 4:
week = "Thursday";
break;
case 5:
week = "Friday";
break;
case 6:
week = "Saturday";
break;
case 7:
week = "Sunday";
break;
default:
week = "Invalid number";
break;
}
System.out.println(week);
}
}
}
4. 然后Ctrl+B运行
最近笔者在编写移动端程序的时候,发现原先是用的@+命令没有效果,一直纳闷是什么原因?
最后发现问题出在安卓上的百度输入法!
百度输入法在中文和英文中提供了两种@符号,请看下图。
经过分析,这两种@符号明显不同,中文版的at符号实际上为:@,在经过unicode解析后,我们发现@的编码为\uff20,而不是我们常见英文@的\u0040。这就导致如果我们PHP写下面的代码,就无效了。我们必须要对另外一种@符号进行判断
笔者之前一直以为@符号是中英文通用,也许是笔者之前的想法是错误的,不过这个符号的确给我带来了一些困扰,不知道百度输入法为什么要使用另外一个@符号呢?

根据HTML标签,属性来进行过滤的类,用于安全处理用户的富文本
在用户前台应用了富文本编辑器,这就使得HTML输出时面临XSS等危险代码的风险。为了解决这个问题,互联网上有很多正则替换的方法,但是都不是很保险且扩展性不高。
后来我在代码仓库中找到了Kses类,这是一个可以根据HTML标签,属性来进行过滤的类,修改了一下就可以适配THINKPHP了。
Kses的版权和相关协议归原作者所有。
———————–我是华丽丽的分割线—————————
Kses大家应该都不陌生,wordpress的富文本内容的过滤应用的就是这个东西。它的安全性还是可以保障的(如果有漏洞希望大家也反馈反馈!,我没进行具体的测试)
我修改后的类文件需要PHP5+THINKPHP3.2环境,如果你不是,请根据源文件和我的修改说明二次开发即可(原作者提供了PHP4的版本….)
下面我只讲解一下常用的方法,更多的方法可以参考附件里面的原作者提供的文档(是英文)。
首先,在配置文件中加入KSES_ALLOWED_PROTOCOL,KSES_ALLOWED_HTML,KSES_ALLOWED_GLOBAL_ATTR元素,他们的意义分别为:允许的协议,允许的HTML元素及其属性,和允许的全局属性。
下面举个例子:
第一,我们允许用户在富文本中使用p元素和a元素,并且p元素不允许使用任何属性,a元素只允许使用href、name和target属性,我们在KSES_ALLOWED_HTML这么写:
'KSES_ALLOWED_HTML' => array(
'p' => array(),
'a' => array(
'href' => true,
'name' => true,
'target' => true,
)),
第二,我们允许用户在富文本中使用http、ftp和mailto连接协议,比如在a元素的href和img元素的src,我们在KSES_ALLOWED_PROTOCOL这么写:
'KSES_ALLOWED_PROTOCOL' => array(
'http',
'ftp',
'mailto',
)),
第三(可选),我们允许用户在富文本中所有HTML元素里使用title,style属性(这回覆盖我们设置的第一个步骤),我们可以在KSES_ALLOWED_GLOBAL_ATTR里这么写:
'KSES_ALLOWED_GLOBAL_ATTR'=>array(
'style' => true,
'title' => true,
),
然后我们在需要执行HTML过滤的地方实例化Kses类
命名空间(这个可能每个人不一样):
use Common\Api\Kses;
然后实例化,使用Parse方法
类似下面这个样子:
$kses = new kses;
exit($kses->Parse(''));
那么如果我们是按照上面3步来设置的,最终会输出
有人问为什么p元素支持style属性,请看第三步
———————–我是华丽丽的分割线—————————
上面是一个全部通过过滤的例子,再举几个不通过的。
如果我们的代码为
那么style2连同后面都会被过滤掉,因为P元素和全局都没有设置允许使用style2属性。
如果我们代码:

整个img元素会被过滤掉,因为我们没有允许使用img元素(请看第一步)
附加!!全局属性请注意:
如果全局属性允许了style,那么系统只允许使用部分安全的CSS属性,比如上面的text-align就可以,但text-align2就不可以了。具体的这个项目在类文件的safecss_filter_attr方法,我已经内置了常用的CSS属性,如果需要扩展请自行修改。
比如我们写代码
那么text-align2这个会被过滤掉
———————–我是华丽丽的分割线—————————
其实Kses还支持很多功能,比如还可以限制某个HTML元素属性填写多少字符的内容,更多的方法请参考附件中Kses的手册。
下面说一下我在类中修改了那些内容,我是从oop/php5.class.kses中修改过来的,只支持PHP5 + THINKPHP3.2哦!
修改日志 ( 2014-4-13 )
1. 增加命名空间,和配置等以适应THINKPHP
2. 修改类名。
3. 2014-4-13 01:21:01 修正参数名称BUG一个。
4. 增加了全局属性,以及CSS检测(也就是例子中的步骤三实现的功能)
大家注意看第三条,这是原作者版本中诡异的拼写错误,在oop/php5.class.kses的958行中,请把string2参数换成string。
我在附件中提供的原版是没有修改这个BUG的(THINKPHP适配版本肯定已经修改了),所以如果你要看原版演示,先把这个拼写错误修复了。
———————–我是华丽丽的分割线—————————
如果有什么问题大家可以再问!谢谢

这些天苦于翻译自己项目管理这一科目的书,虽然每个单词看起来都认识但是很难连接成完整的句子,在网上找了很久终于发现这本书叫做
Project Management: A Systems Approach to Planning, Scheduling, and Controlling
现在把中文版的PDF分享一下